
Groq Llama-3-Tool-Use Models: Top Tool Use & Function Calling
Open-source Models for Advanced Tool Use
We are excited to announce the release of two new open-source models specifically designed for tool use: Llama-3-Groq-70B-Tool-Use and Llama-3-Groq-8B-Tool-Use, built with Meta Llama-3. These models, developed in collaboration with Glaive, represent a significant advancement in open-source AI capabilities for tool use/function calling.
Llama-3-Groq-70B-Tool-Use is the highest performing model on the Berkeley Function Calling Leaderboard (BFCL), outperforming all other open source and proprietary models.
Model Details
- Availability: Both models are now available on GroqCloud™ Developer Hub and on Hugging Face:
- Licensing: These models are released with the same permissive style license as the original Llama-3 models.
- Training Approach: We utilized a combination of full fine-tuning and Direct Preference Optimization (DPO) to achieve state-of-the-art tool use performance. No user data was used in the training process, only ethically generated data.
Benchmark Results
Our models have achieved remarkable results, setting new benchmarks for Large Language Models with tool use capabilities:
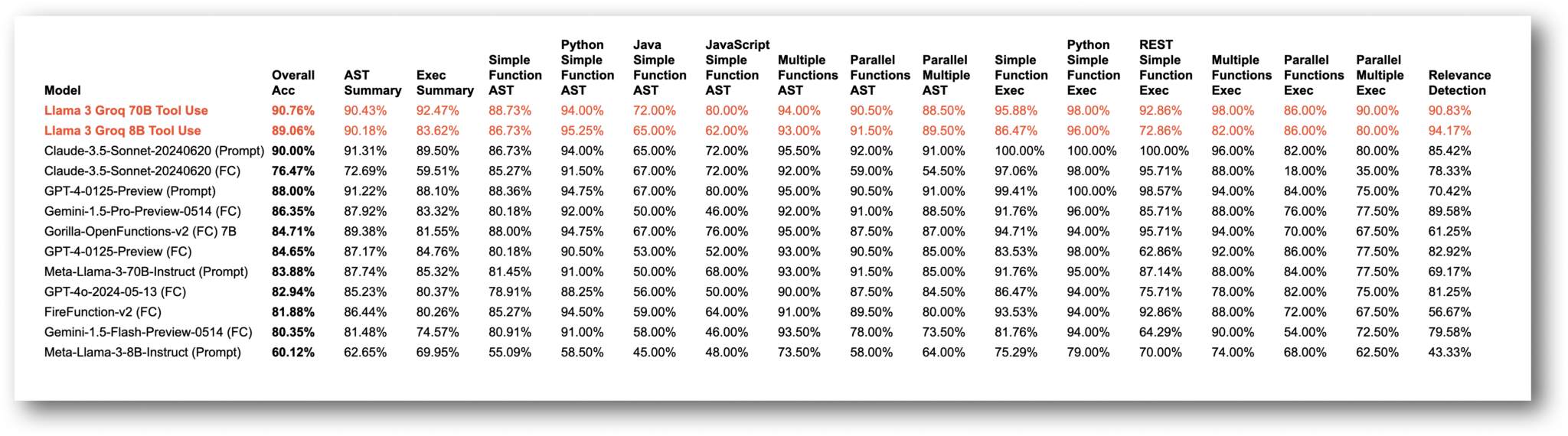
- Llama-3-Groq-70B-Tool-Use: 90.76% overall accuracy (#1 on BFCL at the time of publishing)
- Llama-3-Groq-8B-Tool-Use: 89.06% overall accuracy (#3 on BFCL at the time of publishing)
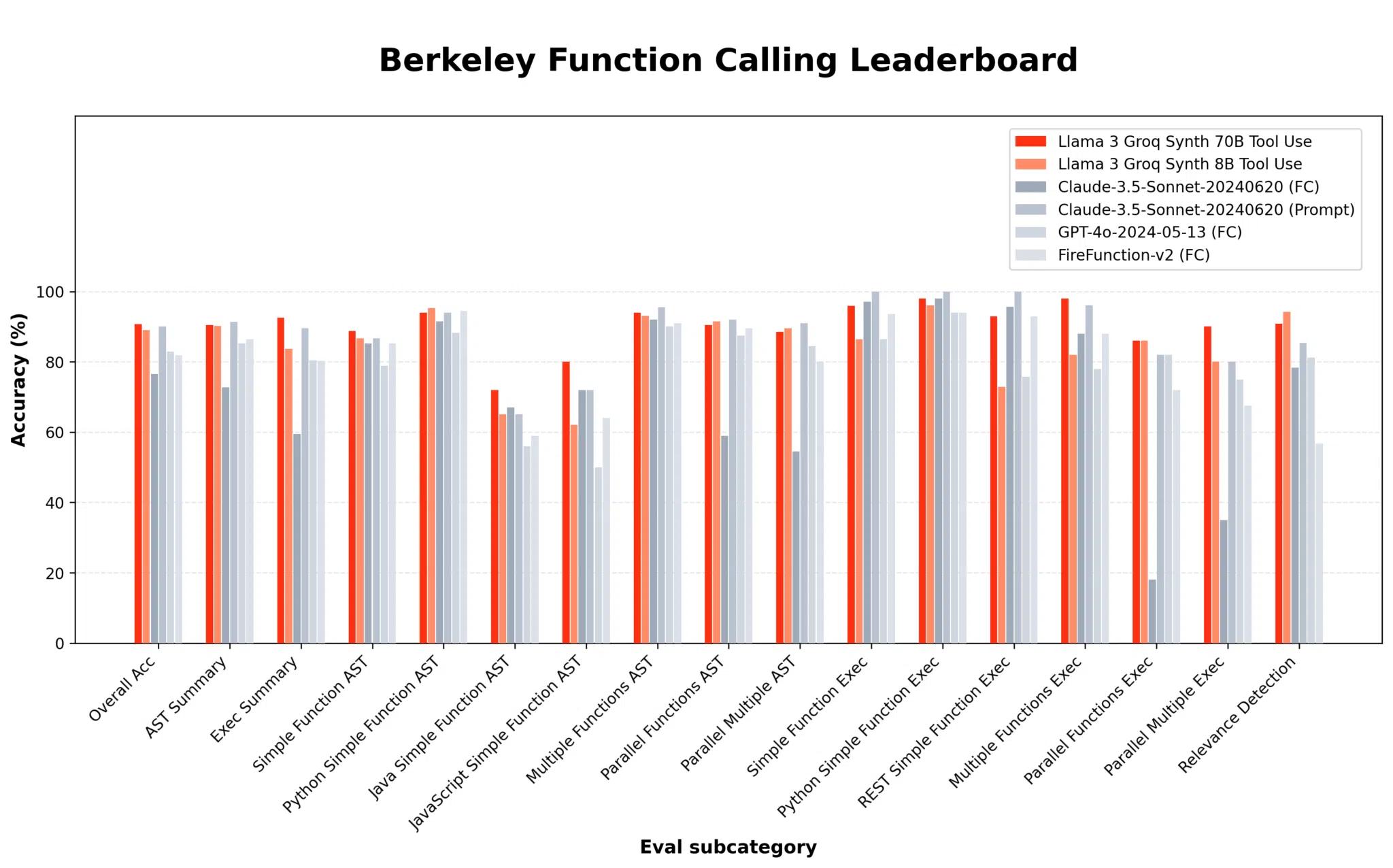
Benchmark results were achieved by running the open source evaluation repository ShishirPatil/gorilla on commit 7bef000.
Detailed performance comparison to other models:
Overfitting
We conducted a thorough contamination analysis using the LMSYS method described in their blog post. The results showed our synthetic data used to fine-tune had a low contamination rate: just 5.6% for the SFT data and 1.3% for the DPO data we trained on relative to test set data in BFCL. Implying there is very limited to no overfitting on the evaluation benchmark.
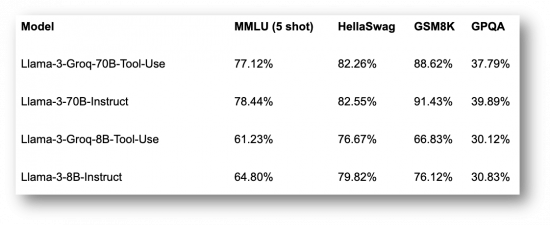
General Benchmark Performance
We’ve carefully selected a learning schedule to minimize the impact on general-purpose performance.
Specialized Models & Routing
While the Llama-3 Groq Tool Use models excel at function calling and tool use tasks, we recommend implementing a hybrid approach that combines these specialized models with general-purpose language models. This strategy allows you to leverage the strengths of both model types and optimize performance across a wide range of tasks.
Recommended approach:
- Query Analysis: Implement a routing system that analyzes incoming user queries to determine their nature and requirements.
- Model Selection: Based on the query analysis, route the request to the most appropriate model:
- For queries involving function calling, API interactions, or structured data manipulation, use the Llama 3 Groq Tool Use models.
- For general knowledge, open-ended conversations, or tasks not specifically related to tool use, route to a general-purpose language model like unmodified the Llama-3 70B.
By implementing this routing strategy, you can ensure that each query is handled by the most suitable model, maximizing the overall performance and capabilities of your AI system. This approach allows you to harness the specialized tool use abilities of the Llama-3 Groq models while maintaining the flexibility and broad knowledge base of general-purpose models.
Conclusion
The Llama-3 Groq Tool Use models represent a significant step forward in open-source AI for tool use. With state-of-the-art performance and a permissive license, we believe these models will enable developers and researchers to push the boundaries of AI applications in various domains.
We invite the community to explore, utilize, and build upon these models. Your feedback and contributions are crucial as we continue to advance the field of AI together.
We’re looking forward to seeing more innovation and experimentation with open-source models and see even higher scores on BFCL to reach full saturation on the benchmark and have solved the first inning of tool use for LLMs.
Start Building
Both Llama-3-Groq-70B-Tool-Use and Llama-3-Groq-8B-Tool-Use are available for preview access through the Groq API with the following model IDs:
llama3-groq-70b-8192-tool-use-previewllama3-groq-8b-8192-tool-use-preview
Get started in the GroqCloud Dev Hub today!