Groq Runs Whisper Large V3 at 164x Real-Time
Whisper Large V3 Is Now Available to the Developer Community via GroqCloud™
We’re excited to announce Groq is officially running Whisper Large V3 on the LPU™ Inference Engine, available to our developer community via GroqCloud™ through our Developer Playground. Whisper is a pre-trained model for automatic speech recognition and speech translation, trained on 680k hours of labeled data. Whisper and models like it are paving the way for accurate and seamless GenAI voice experiences while broadening the possibilities on developer application and use cases, both of which require low-latency AI inference.
This also marks an addition to the expanding GenAI model portfolio hosted by Groq. Large Language Models (LLMs) continue to run on the Groq LPU, the addition of Whisper Large V3 is another step on our way to multi-modal.
Artificial Analysis has included our Whisper performance in their latest independent speech-to-text benchmark.
Dive into the results below. To see see this model in action, check out Project Media QA on GroqLabs. If you are a developer interested in Whisper running on Groq, sign up for access via GroqCloud at console.groq.com.
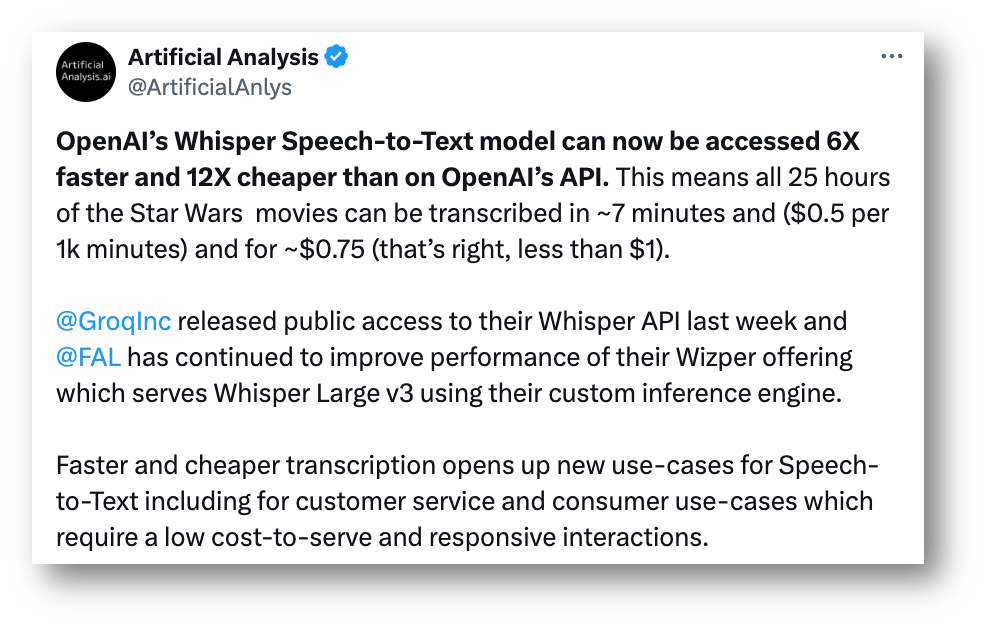
Artificial Analysis has independently benchmarked Whisper Large V3 on Groq as achieving a Speed Factor of 164. This means Groq can transcribe our 10-minute audio test file in just 3.7 seconds. Low latency transcription is a critical component for seamless voice experiences. AI voice experiences require low latency inference on transcription, language, and voice models to enable immediate responses that keep users engaged.
Micah Hill-Smith, Co-founder & CEO, ArtificialAnalysis.ai
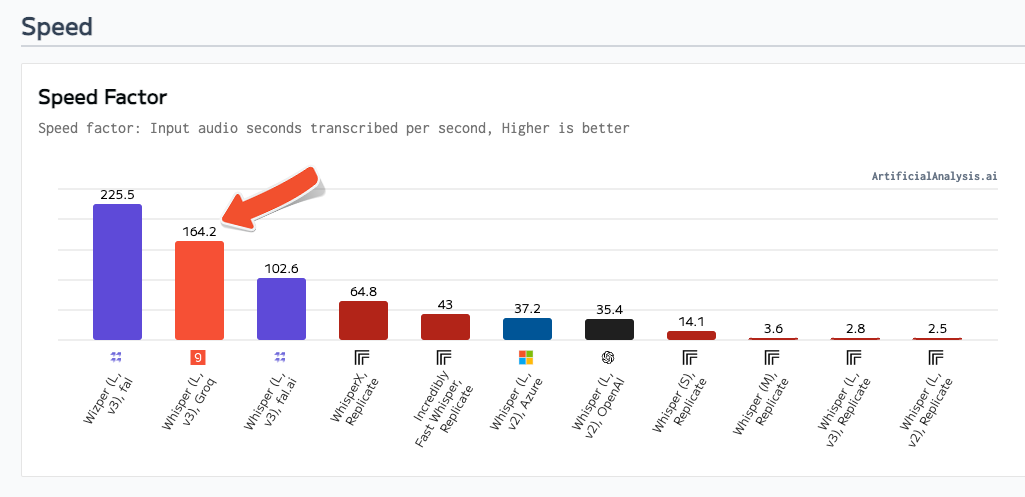
Speed Factor
Measured as input audio seconds transcribed per second, Groq clocks in at a speed factor rate of 164x real-time, the fastest implementation of the base Whisper Large V3 model.
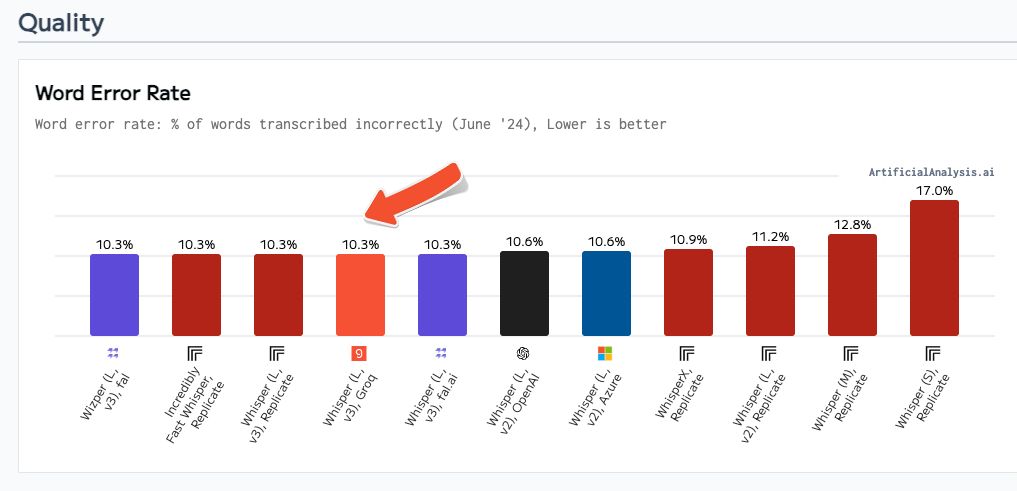
Quality
Artificial Analysis defines Word Error Rate (WER) as the percentage of of words transcribed incorrectly. Groq minimized its Word Error rate to 10.3% for Whisper Large V3, matching the lowest WER from other providers on the leaderboard
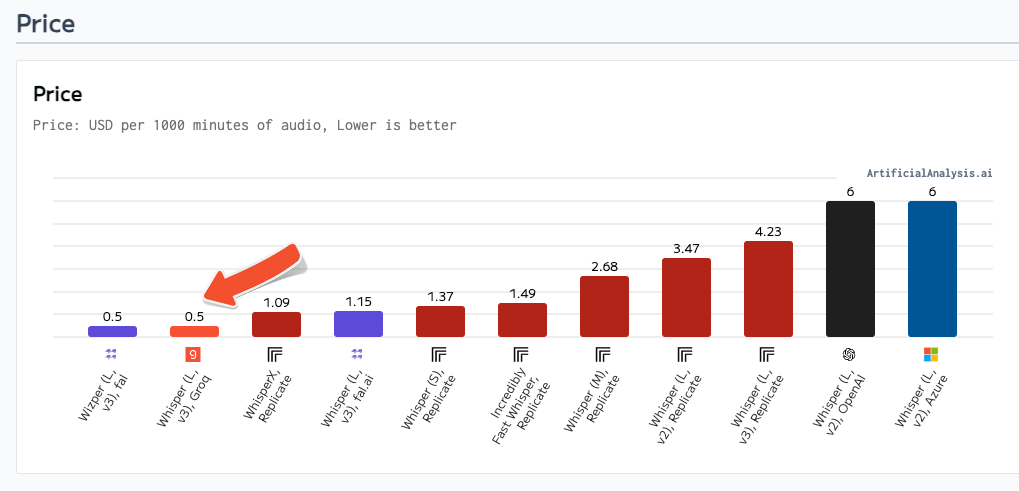
Price
Artificial Analysis defines price as USD per 1000 minutes of audio, bringing the Groq price to $0.5 based on offering Whisper Large V3 at a price of $0.03 per hour transcribed.