
From Speed to Scale: How Groq Is Optimized for MoE & Other Large Models
You know Groq runs small models. But did you know we run large models including MoE uniquely well? Here’s why.
The Evolution of Advanced Openly-Available LLMs
There’s no argument that Artificial intelligence (AI) has exploded, in part because of the advancements in large language models (LLMs). These models have shown some amazing capabilities when it comes to natural language processing, from text generation to complex reasoning. As LLMs become even more sophisticated, one of the biggest challenges is scaling them efficiently. That’s where Groq comes in, a company at the forefront of AI hardware innovation, addressing this challenge with its groundbreaking LPU.
In the past few years, the AI community has seen a surge in open-source LLMs, including models like Llama, DeepSeek, and Qwen. These models have democratized AI – making it possible for researchers and developers to access cutting-edge AI technology without being limited by proprietary systems. As a result, we’ve seen the emergence of smaller, more efficient models, as well as larger, more powerful ones. While smaller models are ideal for more general purpose tasks, larger models push the boundaries of what is possible in AI, offering unparalleled performance on complex tasks.
Groq LPU: Uniquely Designed To Handle Small to Very Large Models Across a Variety of Architectures, Including MoE
The Groq® LPU™ architecture was built from the ground up to address the challenges of scaling AI workloads. While legacy hardware like GPUs often struggle to scale latency, the LPU is optimized for near-linear scalability, enabling real-time AI applications. Individual Groq LPU chips are designed to interconnect and create one shared resource fabric for models to run on – this is possible because of Groq Compiler and Groq RealScale™ chip-to-chip interconnect technology. This means Groq efficiently runs very large models across a variety of model architectures without bottlenecking output speeds –something that has become critically important with increasing model sizes and new architectures like mixture of experts (MoE). For example, Groq’s LPU deployed Meta’s Llama 4 Maverick, a 400B parameter state-of-the-art openly-available MoE LLM, on the same day as its release – Groq can deliver the scale and pace needed to keep up with the ever-changing AI model landscape.
In the past few years, the AI community has seen a surge in open-source LLMs, including models like Llama, DeepSeek, and Qwen. These models have democratized AI – making it possible for researchers and developers to access cutting-edge AI technology without being limited by proprietary systems. As a result, we’ve seen the emergence of smaller, more efficient models, as well as larger, more powerful ones. While smaller models are ideal for more general purpose tasks, larger models push the boundaries of what is possible in AI, offering unparalleled performance on complex tasks.
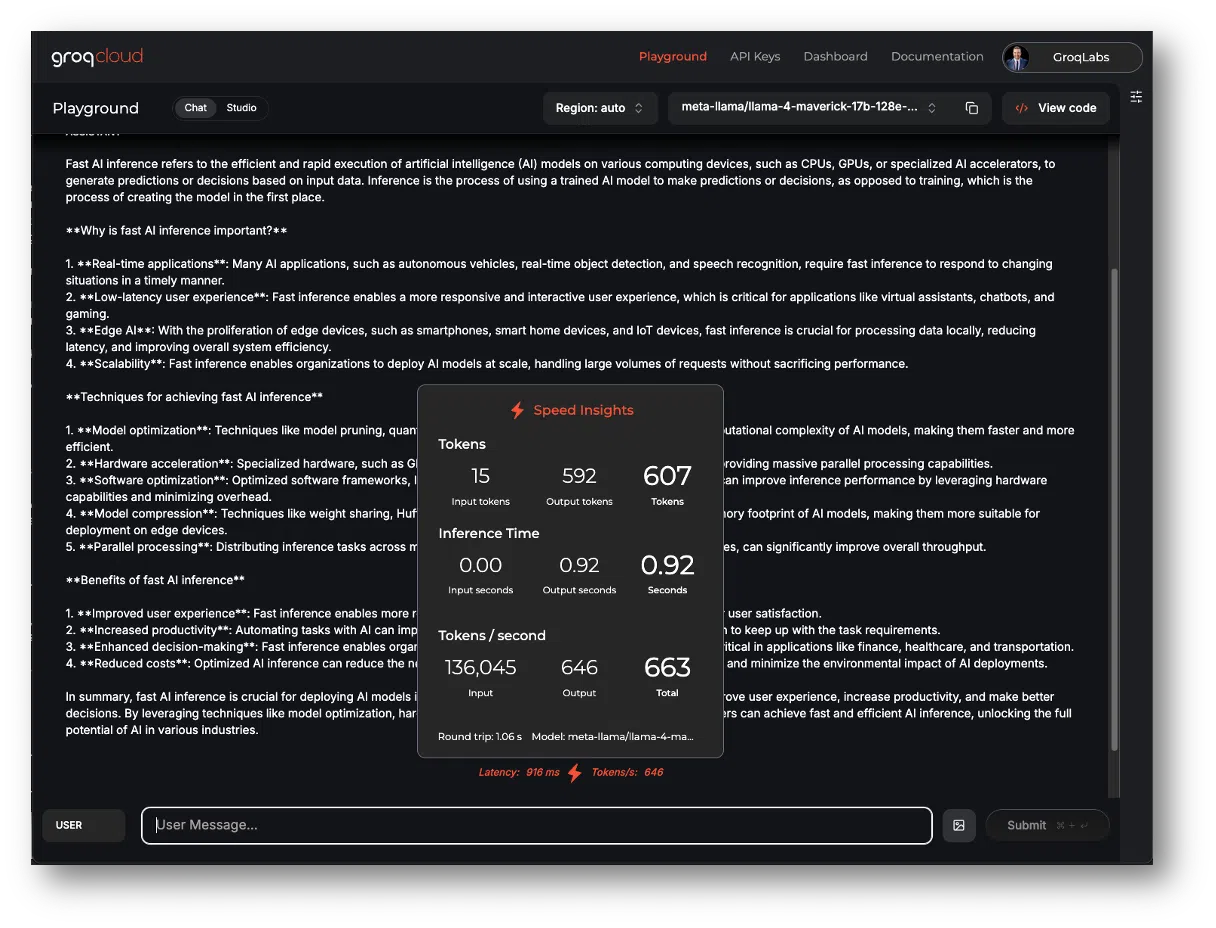
Selecting an Inference Provider: Prioritize Efficient AI Inference
While selecting or switching to an inference provider that supports a variety of models is important, not all AI inference is created equal. Some key considerations include:
- Token Cost: As user base and model usage grow, so do inference bills. Groq provides low token prices across all supported models in GroqCloud.
- Latency: Latency is a critical factor in real-time applications. Groq’s LPU is engineered to minimize latency, ensuring that even large models can respond quickly to user inputs.
- Output speed: Fast inference speeds are essential for production environments. The LPU architecture is optimized for high-throughput inference.
- Context window: Large context windows are often necessary for complex tasks. Groq’s LPU is designed to handle them efficiently.
- Enabled model features: Streaming, Tool Use, and JSON mode are increasingly critical. Groq enables these features across supported models in GroqCloud.
Groq’s LPU is a significant advancement in AI hardware, offering the scalability and efficiency needed to support both small and large models. Simply put, Groq’s purpose-built LPU architecture is better for inference. To learn more, check out our LPU blog.
Start building today on GroqCloud – sign up for free access or scale without rate limits by upgrading to a GroqCloud paid tier.