
Whisper Large v3 Turbo – Fast Speech Recognition Now on Groq
We’re excited to announce that Whisper Large v3 Turbo (whisper-large-v3-turbo) is now available to the developer community on GroqCloud™ Developer Console. This pruned and fine-tuned version of OpenAI’s Whisper model complements the existing Automatic Speech Recognition (ASR) models, Whisper Large V3 and Distil-Whisper, and is designed to provide faster and less expensive multilingual speech recognition while maintaining comparable accuracy (vs Whisper Large v3).
Whisper Large v3 Turbo provides an incredible balance of the benefits of Whisper Large v3 and Distil-Whisper in terms of speed, quality, and capabilities. At 216x real-time speed factor it is faster than Whisper Large v3 while maintaining multilingual capabilities and has a ~1% lower Word Error Rate (WER) than Distil-Whisper.
The addition of Whisper Large v3 Turbo to GroqCloud expands the range of Automatic Speech Recognition (ASR) options available to developers, providing a faster and more efficient alternative to the original Whisper Large v3 model.
This new model is ideal for applications that require rapid multilingual speech recognition, such as:
- Real-time customer service chatbots that need to quickly transcribe customer inquiries and respond with personalized solutions
- Automated speech-to-text systems for industries like finance and education, where fast and accurate transcription is critical
- Voice-controlled interfaces for smart homes, cars, and other devices, where rapid speech recognition is essential
- Audio and video recording transcriptions – such as interviews, lectures, podcasts, and TV shows – for media professionals, enabling them to focus on editing, analysis, and other tasks
- Transcription and summarization (in conjunction with LLMs) that can used on meeting recordings to create a list of action items and decisions or simplify the process of insurance claims and improve service by transcribing recordings of interviews, phone calls, and other interactions with customers
Performance
Artificial Analysis has included our Whisper Large v3 Turbo performance in their latest independent speech-to-text benchmark. Measured as input audio seconds transcribed per second, Groq’s implementation of Whisper Large v3 Turbo clocks in at a speed factor rate of 216x real-time.
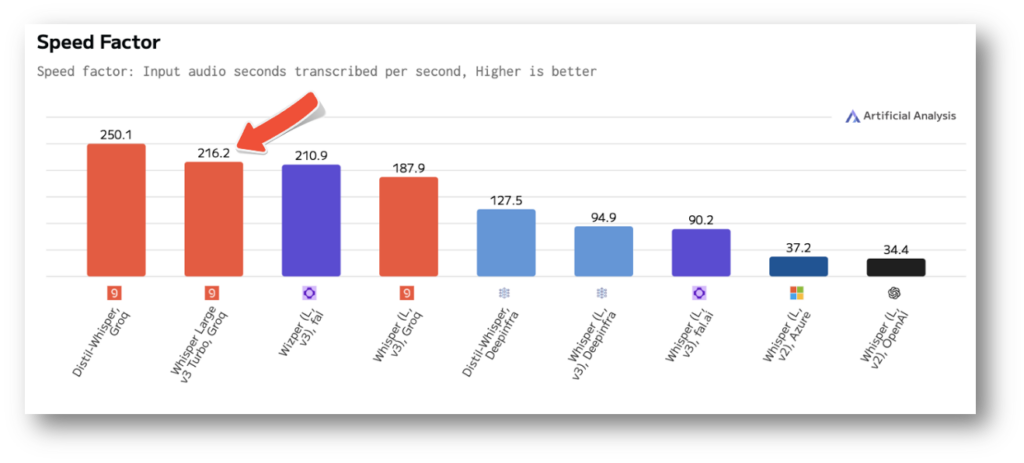
Whisper Model Comparisons on Groq
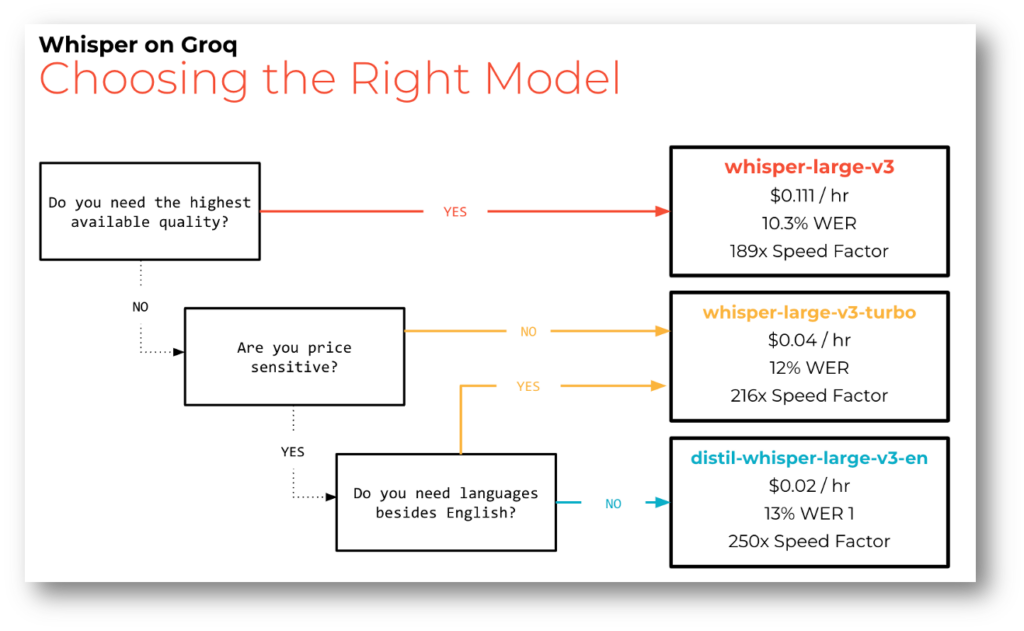
Not sure which model is best for your usage? See below for a quick comparison of the three models as well as a decision tree to help guide you.

Pricing
We’re excited to offer Whisper Large v3 Turbo at a competitive on-demand price of $0.04 per hour, making it an attractive option for developers and enterprises looking to improve their multilingual speech recognition capabilities without breaking the bank.
Private dedicated instances of all three Whisper models are also available. Contact sales@groq.com for pricing and details.
We’re committed to fueling the open AI ecosystem, in part by providing developers with access to leading AI models that are driving innovation. Adding Whisper Large v3 Turbo to GroqCloud is one more step in this direction. Given its speed and accuracy, we’re anticipating everyone from the developer to the enterprise will be utilizing Whisper Large v3 Turbo for a wide range of applications.