
Retrieval Augmented Generation with Groq API
The emergence of Large Language Models (LLMs) has played a pivotal role in transforming the way we interact with information. Like any technology, they come with their limitations:
- LLMs are trained on massive datasets and their knowledge is fixed at the time of training. These models learn from a diverse range of data, capturing patterns and information available up to a certain cutoff date. Once the training is complete, the model's knowledge becomes static and does not dynamically update with real-time information.
- Most LLMs are absent of domain-specific knowledge because they are trained on open-source datasets. During their training phase, these models learn from a broad spectrum of topics, making them proficient in a wide range of subjects. However, this breadth comes at the expense of depth in any specific domain.
- LLMs sometimes generate answers that, while seemingly plausible, reasonable, and coherent, are factually incorrect, nonsensical, or not grounded in reality.
Enter Retrieval Augmented Generation (RAG), an approach that addresses some of the limitations of LLMs and promises to revolutionize the way we leverage proprietary, organization specific information. This blog will discuss how RAG can alleviate some of these limitations, how to connect proprietary data to the Groq API, and what this means for organizations.
https://youtu.be/QE-JoCg98iU
What is Retrieval Augmented Generation?
RAG is a technique to mitigate the limitations associated with LLMs mentioned above. RAG combines the strengths of both information retrieval methods and LLMs, offering a hybrid approach that enhances contextual understanding, improves content accuracy, and adds a layer of trustworthiness.
In essence, RAG harnesses pre-existing knowledge through a retrieval mechanism, allowing the model to pull in relevant information from a vast repository of data (e.g., unstructured data like text stored in a Vector Database like Pinecone or structured data stored in a SQL database). This ensures that the generated content is not only contextually accurate but also grounded in real-world information. By augmenting generation with retrieval, RAG aims to bridge the gap between traditional LLMs and human-like understanding. An illustration of a RAG architecture can be seen in Figure 1.
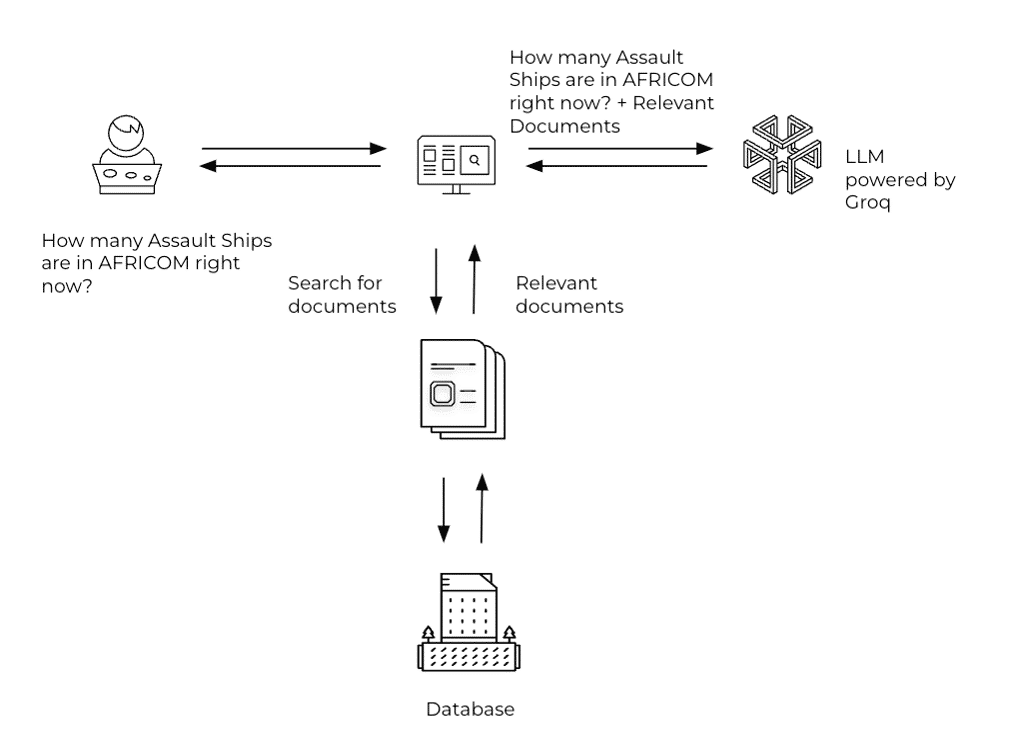
How does RAG help reduce the limitations of LLMs?
LLMs are poised to augment federal enterprises and missions, fostering natural, user-focused interactions with agency-specific data. However, a closer examination of LLMs reveals several limitations that have spurred the need for innovative solutions like RAG. Below are some of the benefits introduced by integrating RAG into an LLM application.
Dated Models and Information: RAG ensures the responsiveness of LLMs by consistently aligning generated responses with the latest, precise information sourced from an external database. This addresses the challenge of LLMs struggling to adapt to evolving data, allowing seamless retrieval of proprietary business data at generation time.
Absence of domain specific knowledge: LLMs, trained on diverse open datasets, excel in generalized tasks but face limitations in domain-specific applications. RAG overcomes this hurdle by enriching the model's context with domain-specific data from an organization's knowledge base. Its capacity to retrieve and incorporate specific information makes it an ideal solution for nuanced responses in dynamic information environments, catering to scenarios demanding precision, flexibility, and specificity.
Inaccurate but plausible answers: The generation of inaccurate yet seemingly plausible responses, commonly referred to as "hallucination," is a phenomenon where a LLM produces text that is factually incorrect, nonsensical, or unreal but presents itself as believable. The adoption of RAG contributes to the reduction of hallucinations by grounding the model's output in accurate and factual information. RAG combines generative capabilities with information retrieval, leveraging external knowledge to enhance the accuracy, contextuality, and reliability of the generated responses, thereby mitigating the issue of inaccurate but plausible answers.
Addressing these limitations is crucial for enhancing the overall reliability and utility of LLMs, particularly in mission critical contexts.
Integrating RAG with Groq in a couple lines of code.
Integrating proprietary data with the Groq API is very straightforward. The instructions below outline the steps to connect your own database to the Groq API via Python. To follow the steps in this post you will need the following:
- Data stored in a Vector Database (this demo utilizes Pinecone).
- Set up a free account with Pinecone and create an index on a free tier and follow this guide to download sample data and index it into Pinecone.
- A Groq API key - get yours for free today at console.groq.com
1. Connect to your database
1import pinecone
2
3pinecone.init(
4 api_key='xxxx',
5 environment='xxxx'
6)
7pinecone_index = pinecone.Index('name-of-index')2. Convert questions into a vector representation
Use an embedding model to convert questions into a vector representation. This blog does not focus on what an embedding model is. For more information, please check out this link.
1from transformers import AutoModel
2
3embedding_model = AutoModel.from_pretrained(
4 'jinaai/jina-embeddings-v2-base-en',
5 trust_remote_code=True
6)
7
8user_query = "user query"
9query_embeddings = embedding_model.encode(user_query).tolist()3. Query your database
1result = pinecone_index.query(
2 vector=query_embeddings,
3 top_k=5, #this is the number of results that are returned
4 include_values=False,
5 include_metadata=True
6)4. Add the retrieved information to the LLM system prompt.
This provides information to the LLM about how to act and respond.
The exact json fields will depend on how you structured your index.
1matched_info = ' '.join(item['metadata']['text'] for item in result['matches'])
2sources = [item['metadata']['source'] for item in result['matches']]
3context = f"Information: {matched_info} and the sources: {sources}"
4sys_prompt = f"""
5Instructions:
6- Be helpful and answer questions concisely. If you don't know the answer, say 'I don't know'
7- Utilize the context provided for accurate and specific information.
8- Incorporate your preexisting knowledge to enhance the depth and relevance of your response.
9- Cite your sources
10Context: {context}
11"""5. Ask GroqAPI to answer your question
Export your Groq API key in your terminal i.g. export GROQ_SECRET_ACCESS_KEY=""
1from groq.cloud.core import Completion
2
3with Completion() as completion:
4 response, id, stats = completion.send_prompt(
5 "llama2-70b-4096",
6 user_prompt=user_query,
7 system_prompt=sys_prompt
8 )In the context of the Public Sector, despite the unique challenges that customers may encounter, leveraging the advantages of LLMs remains feasible. RAG can be a strategic approach for anchoring LLMs in the most current and verifiable information, concurrently mitigating the expenses associated with recurrent retraining and updates. By enhancing the reliability and accuracy of responses, RAG contributes to building user trust in the system, a crucial element within the Public Sector where transparency and precision are paramount. This not only positions LLMs as a potential force multiplier but also establishes a foundation of confidence in the effectiveness and dependability of the system. For customers operating in highly regulated or classified environments where data is stored on-premises and systems remain disconnected from the internet, this design pattern can be seamlessly adopted. For a more in-depth understanding, please reach out to GroqLabs, where our experts can provide comprehensive insights and guidance tailored to specific requirements.
Potential Examples of how Public Sector Organizations can leverage LLMs with RAG:
- The Department of the Navy can harness the power of LLMs and RAG to revolutionize its manpower analysis system(s). RAG could help procure the most up to date information about personnel qualifications, vessels, and other operational units. While, the LLMs can assist in processing vast amounts of data, enabling more accurate matching of personnel to jobs. This approach not only improves efficiency in personnel assignment but also ensures that the Navy deploys individuals with the right expertise to enhance overall operational effectiveness. This advanced manpower analysis system contributes to a more agile and adaptive force, better equipped to meet the evolving challenges of maritime operations.
- The Department of Labor could benefit from the strategic deployment of LLMs and RAG in the creation of memoranda incorporating results from diverse analyses and pertinent information extracted from databases. Through the application of a RAG architecture, the department can expeditiously access and assimilate intricate datasets, ensuring the production of memos characterized by accuracy and comprehensiveness. This approach not only expedites the memo composition workflow but also elevates the overall quality of communication by presenting data-driven insights with precision and clarity.
This blog has demonstrated how customers can optimize their utilization of proprietary data in conjunction with open source LLMs running on our hardware to extract the full power of LLMs. You can use these code snippets as is or you may customize them to your needs. To customize, you can use your own set of documents in the knowledge library, use other Vector Databases like Milvus, use other embedding models, and text generation LLMs available on Groq API.