
New AI Inference Speed Benchmark for Llama 3.3 70B, Powered by Groq
Artificial Analysis Benchmarks Groq LPU™ Fast AI Inference Same Day as Meta Release
It hasn’t even been a day since Meta released Llama 3.3 70B and just like that, Artificial Analysis has already benchmarked Groq LPU™ performance. Here’s a quick overview of the results – you can deep dive into the full report from Artificial Analysis here.
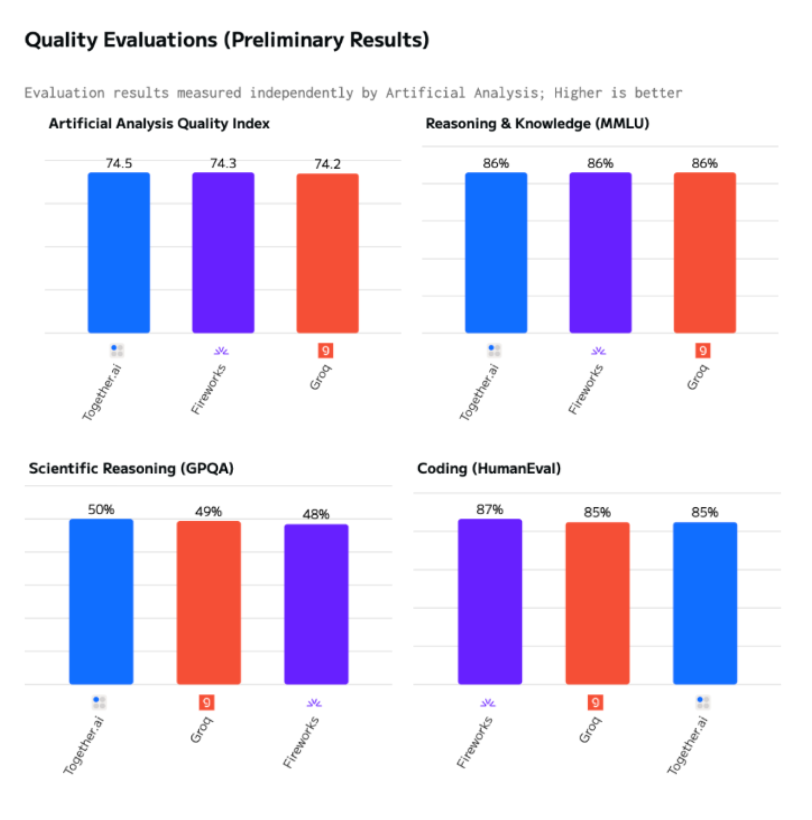
Overall Model Quality Evaluations
By leveraging new post-training techniques, Meta has improved performance across the board, reaching state-of-the-art in areas like reasoning, math, and general knowledge. What’s impressive is that this model delivers results similar in quality to the larger 3.1 405B model. Below you can see the Llama 3.3 70B to Llama 3.1 70B comparison on Groq. Note these are the first third party industry-standard quality benchmarks showcasing this comparison.
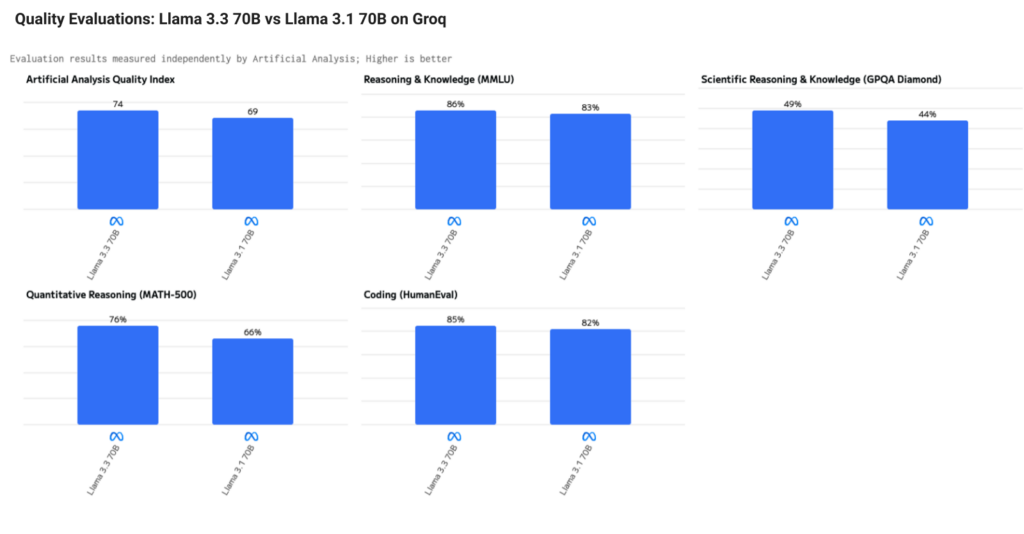
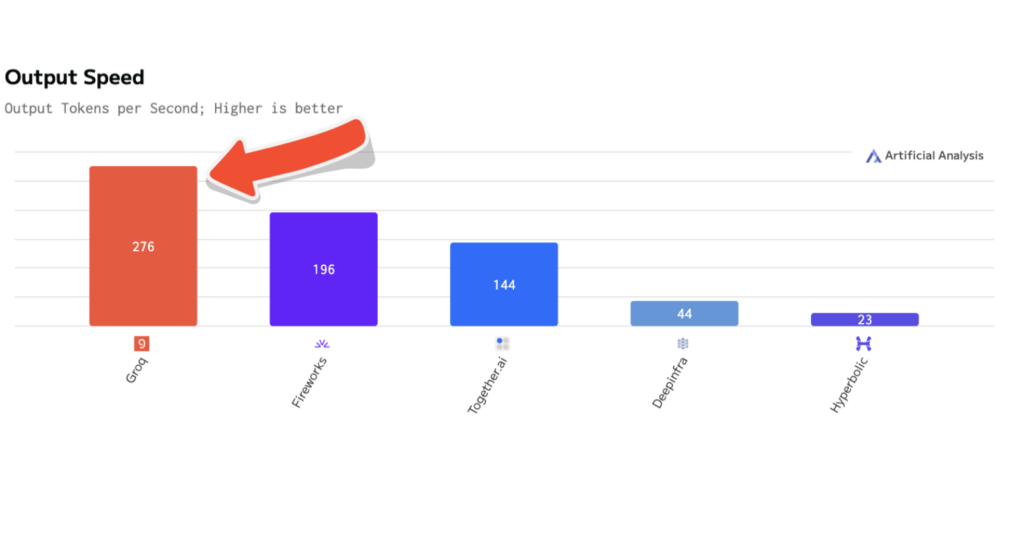
Performance
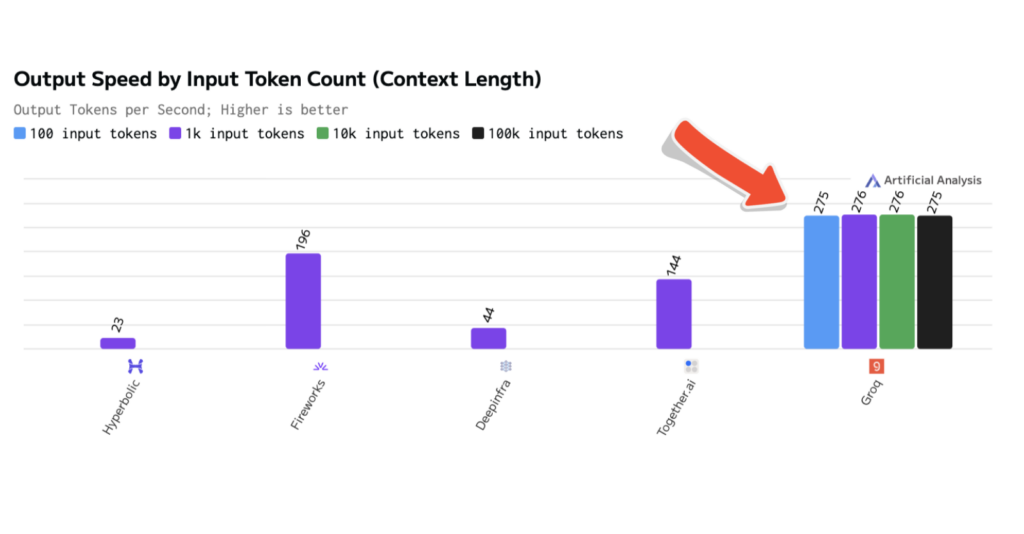
Artificial Analysis has independently benchmarked Groq performance of Llama 3.3 70B at 276 tokens per second, the fastest of all benchmarked providers.
This is 25 T/sec faster than our performance on the original model, Llama 3.1 70B.
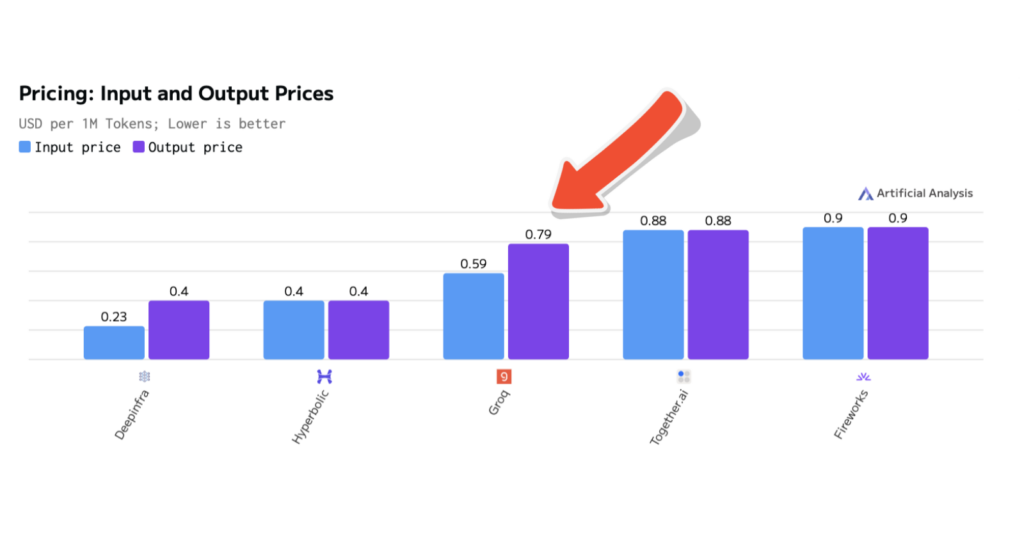
Pricing
Groq offers Llama 3.3 70B Versatile 128k at an input price of $0.59 per million tokens (1.69M / $1) and an output price of $0.79 per million tokens (1.27M / $1). See all Groq pricing here.
Context Length & Speed
Context length refers to the maximum number of tokens (words, characters, or subwords) that an LLM can process in a single input. This limit is typically determined by the model’s architecture, training data, and computational resources.
Context length can have a significant impact on an LLM’s performance, particularly in business applications where accuracy and relevance are required. A longer context length generally allows for higher quality outputs, while a shorter length leads to faster performance. In this case, Groq is able to provide consistent speed (275-276 T/sec) across all input token counts tested, meaning developers and enterprises don’t have to make a tradeoff.
Read more about the impact of context length on LLM performance here.
Why It Matters
So what does all this actually mean for developers and enterprises building with Llama 3.3 70B? Llama 3.3 70B shows particular strength in multilingual capabilities and maintains strong performance on long-context tasks, proving that smaller models can deliver top-tier results when properly optimized. In practical terms, users can expect:
- Step-by-step chain of thought reasoning outputs with more accurate responses
- Broader coverage of top programming languages, with greater accuracy
- Improved code feedback that helps identify and fix issues, as well as improved error handling
- Enhanced JSON function calling capability
Access Llama 3.3 70B Powered by Groq now on GroqCloud™ Developer Console where you can get your free API key and start building today.