
Groq 14nm Chip Gets 6x Boost: Launches Llama 3.3 70B on GroqCloud
We're excited to announce the release of Llama 3.3 70B Speculative Decoding (llama-3.3-70b-Specdec) on GroqCloud, a >6x performance enhancement (vs Llama 3.1 70B on Groq)
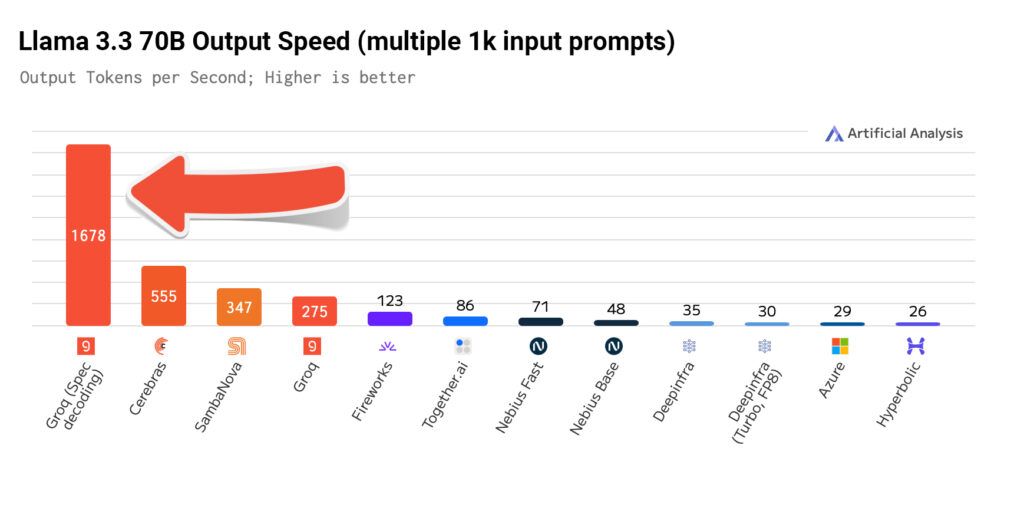
Our team achieved this performance jump from 250 T/s to 1660 T/s on our 14nm LPU architecture with software updates alone, and aren’t hitting a saturation point on our first generation silicon anytime soon. We’re excited for what this will mean for future performance potential as new models enter the AI ecosystem and as Groq matches that innovation with V2 hardware. This new version of Llama 3.3 70B Powered by Groq implements speculative decoding, a process that leverages a smaller and faster 'draft model' to generate tokens that are verified on the primary model. This innovative approach enables faster and more efficient processing, making it ideal for applications that require rapid and accurate language understanding.
“Artificial Analysis has independently benchmarked Groq as serving Meta’s Llama 3.3 70B model at 1,665 output tokens per second on their new endpoint with speculative decoding. This is >6X faster than their current Llama 3.1 70B endpoint without speculative decoding and >20X faster than the median of other providers serving the model. Speculative decoding involves using a smaller and faster ‘draft model’ to generate tokens for the primary model to verify.Our independent quality evaluations of Groq’s speculative decoding endpoint confirm no quality degradation, validating Groq’s correct implementation of the optimization technique. Meta’s Llama 3.1 70B is the most commonly used open source AI model. This new endpoint will support developers in building for use-cases which benefit from fast inference including AI agents and applications which require real-time responses."
George Cameron, Co-Founder, Artificial Analysis
Fast AI inference, like what Groq is providing for llama-3.3-70B-specdec, is helping to unlock the full potential of GenAI. Pushing the boundaries of speed is helping make AI models more useful to real-world applications, enabling developers to build more intelligent and capable applications, and increase the intelligence and capability of openly-available models.
The context window for llama-3.3-70b-specdec starts at 8k and will provide significant benefits for a wide range of applications, including but not limited to:
- Agentic workflows for content creation: With llama-3.3-70B-Specdec, developers can build agentic workflows that can generate high-quality content such as articles, social media posts, and product descriptions, in real-time.
- Conversational AI for customer service: llama-3.3-70B-Specdec can be used to build conversational AI models that can understand and respond to customer inquiries in real-time.
- Decision-making and planning: With llama-3.3-70B-Specdec, developers can build AI models that can analyze complex data and make decisions in real-time.
We're committed to making this model more broadly available in the coming weeks. For now, paying customers will have exclusive access to llama-3.3-70B-specdec.
Performance
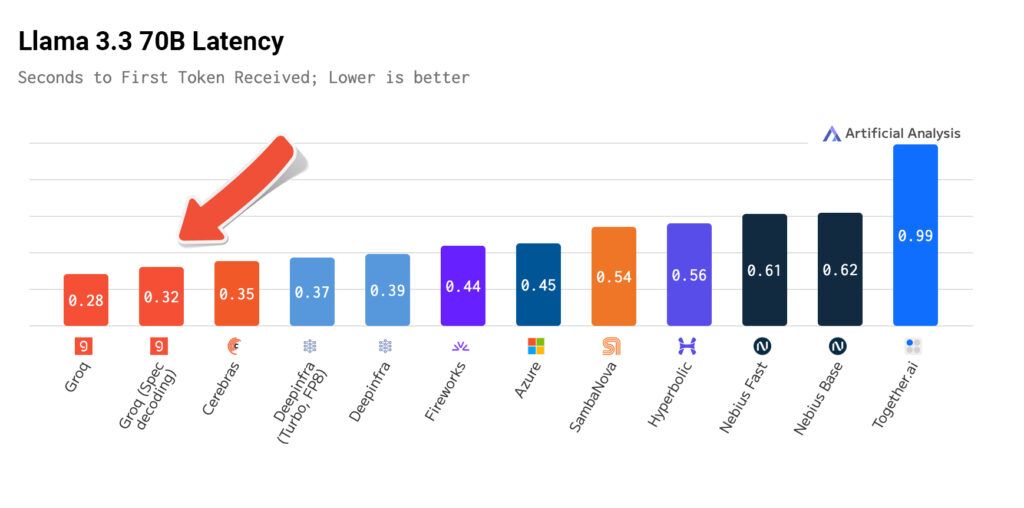
Artificial Analysis has included our llama-3.3-70B-specdec performance in their latest independent Llama 3.3 70B benchmark. See an overview of the results below and dive into the full report by Artificial Analysis here.
Pricing
We're excited to offer llama-3.3-70B-Specdec at a competitive on-demand price of $0.59 per million input tokens and $0.99 per million output tokens. At this price, developers and enterprises can improve their LLM inference capabilities without breaking the bank.
At Groq, we're dedicated to fueling the open AI ecosystem by providing developers with access to leading AI models that drive innovation. The release of llama-3.3-70B-Specdec on GroqCloud is another step in this direction, and we're eager to see the impact it will have on the developer community. If you haven't already, get started with a free API key from GroqCloud Developer Console.