
GPT‑OSS Improvements: Prompt Caching & Lower Pricing
At Groq, we’re relentless about fueling developers with the best price‑performance for AI inference. Today we’re starting to roll out two updates for GPT-OSS models that make building at scale faster, cheaper, and simpler.
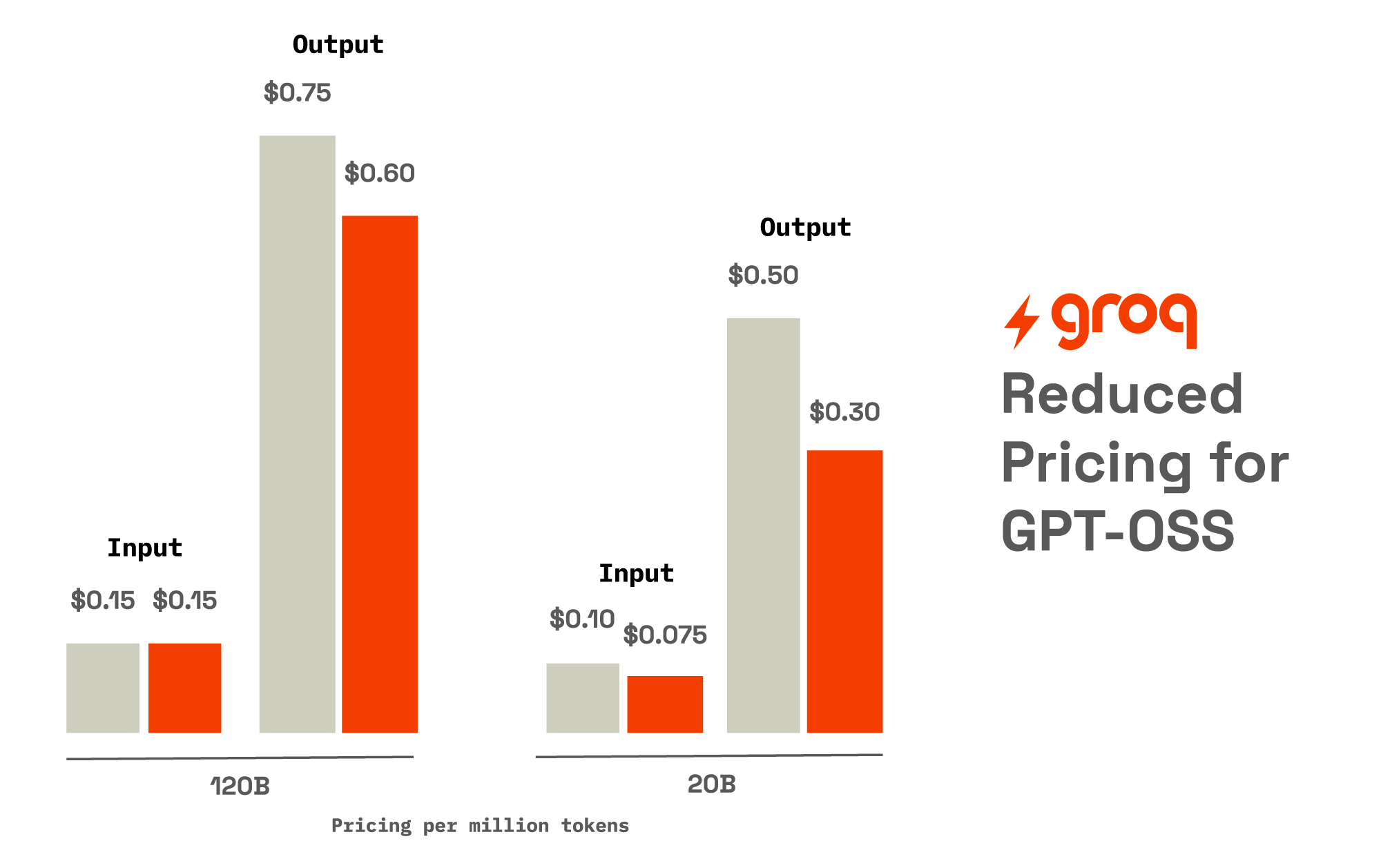
New, Lower Prices for GPT‑OSS Models
We’ve reduced the price for gpt-oss models on GroqCloud to ensure all developers can ignite their applications with increased cost efficiency. These new prices are effective today and will apply retroactively to all unpaid invoices for the month of October 2025.
Prompt Caching on GPT-OSS Models
We’re rolling out prompt caching on our GPT-OSS models. Last month we quietly rolled out prompt caching on GPT-OSS-20B, and we’ll be rolling it out on GPT-OSS-120B over the next few weeks. What this means for developers using these models:
- Up to 50% discount on cached tokens - All input tokens in the identical prefix get a 50% discount; the tokens after the first difference between prompts are charged at full price.
- Significantly lower latency – Reduced latency for any request that shares an identical token prefix with a recent request.
- Rate limits go farther - All cached tokens don’t count towards GroqCloud rate limits.
- Zero configuration – Pricing updates and prompt caching work automatically on every API request. No code changes required.
The 50 % discount on cached input tokens alongside the reduced pricing for GPT-OSS models improves cost efficiency for inference workloads.
| Model | Input Price for uncached tokens (Per 1M Tokens) | Input Price for Cached Tokens (Per 1M Tokens) |
|---|---|---|
openai/gpt-oss-120b | $0.15 | $0.075 |
openai/gpt-oss-20b | $0.075 | $0.0375 |
At Cluely, we specialize in real-time AI, where latency is critical. We already leverage Groq for our most time-sensitive generations, and implementing prompt caching will not only accelerate our product but also enable entirely new use cases. With an average of 92% prompt reuse across our generations. Implementing prompt caching will be game-changing for both speed and quality.
Why Prompt Caching Matters on GPT-OSS Models
Prompt caching makes AI workflows faster and lower cost. It’s ideal for any workflow with stable, reusable prompt components and works automatically on every API request. Here are a few example use cases well suited for GPT-OSS models that can benefit from prompt caching:
- RAG platforms & data apps: Long system prompts + retrieval templates are cached and reused across queries.
- Agentic applications: Repetitive tool/function calls and shot examples are re‑used across calls.
- Eval pipelines: Identical prompts across large datasets are served from cache and reused across queries.
- Chatbots: Persistent brand/style & policy preambles are cached and reused across queries.
How Prompt Caching Works
- Prefix Matching: The system identifies matching prefixes from recent requests. Prefixes can include system prompts, tool definitions, few-shot examples, and more. Note: prefixes can only match up to the first difference, even if later parts of the prompt are the same!
- Cache Hit: If a matching prefix is found, cached computation is reused, dramatically reducing latency and token costs by 50% for cached portions.
- Cache Miss: If no match exists, your prompt is processed normally, with the prefix temporarily cached for potential future matches.
- Automatic Expiration: All cached data automatically expires within a few hours.
Ready to take your GPT-OSS build to the next level?
With built-in tools, Responses API, and instant cloud availability in four global regions, Groq offers the most robust feature support for gpt-oss models. This alongside lower token costs and prompt caching support means developers now have even more fuel to power their applications.
Start experimenting with GPT-OSS models on GroqCloud today. To learn more about prompt caching and best practices check out our developer documentation.