Groq LPU™ Inference Engine Crushes First Public LLM Benchmark
Groq Delivers up to 18x Faster LLM Inference Performance on Anyscale’s LLMPerf Leaderboard Compared to Top Cloud-based Providers
Hey Groq Prompters! We're thrilled to announce that Groq is now on the LLMPerf Leaderboard by Anyscale, a developer innovator and friendly competitor in the Large Language Model (LLM) inference benchmark space. This benchmark includes a selection of LLM inference providers and the analysis focuses on evaluating for performance, reliability, and efficiency measured by:
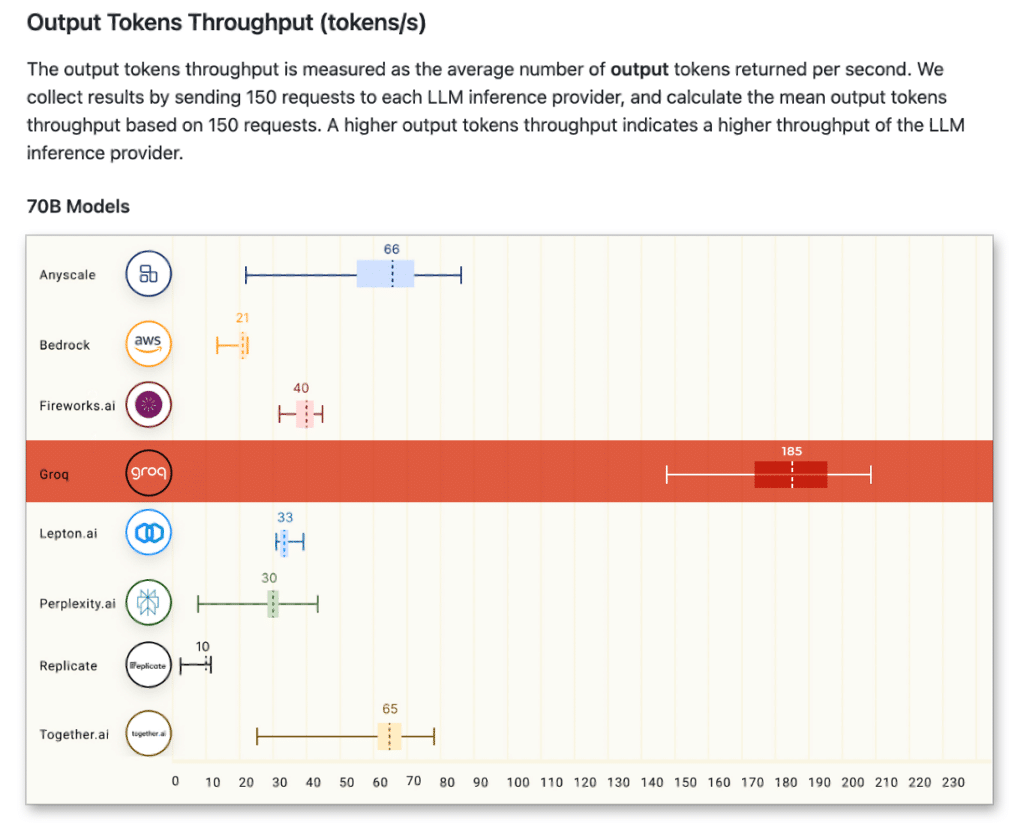
- Output Tokens Throughput (tokens/s): The average number of output tokens returned per second. This metric is important for applications that require high throughput, such as summarization and translation, and easy to compare across different models and providers.
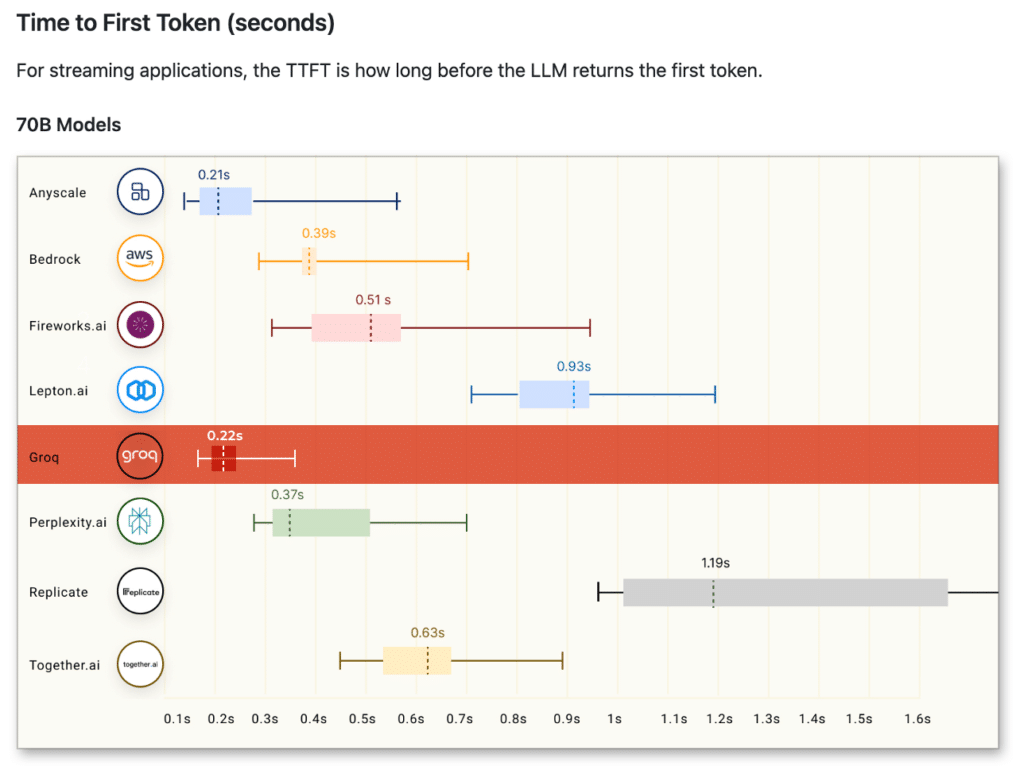
- Time to first token (TTFT): The duration of time that LLM returns the first token. TTFT is especially important for streaming applications that require low latency such as chatbots.
Not only is this our first public benchmark - it was a huge success. Meta AI’s Llama 2 70B running on the Groq LPU™ Inference Engine outperformed all other cloud-based inference providers at up to 18x faster for output tokens throughput.
Let’s walk through the Anyscale methodology in a bit more detail. This benchmark leverages:
- A 550 input token count and a 150 output token count
- The first metric, Output Tokens Throughput (aka the output speed) is determined by dividing the count of output tokens by the overall end-to-end time, which includes input tokens processing time and overall network latency.
- For a full list of caveats and disclaimers for this benchmark, please refer to the documentation here.
On our end, we’d like to note:
- All Llama 2 calculations on the LPU are done in FP16, but we store some of the weights in FP8.
- We have no sparsity (i.e. we’re doing ALL of the Llama 2 matrix calculations and thus processing the entire model as provided by Meta AI).
- This is noteworthy in general as FP16 should provide a higher quality of results for inference.
Now let’s look a bit more closely at the results for each metric.
For Output Tokens Throughput, Groq achieved an average of 185 tokens/s, a result that ranges 3-18x faster than any other cloud-based inference provider contributing to the leaderboard.
For Time to First Token, we hit 0.22s. Because of the deterministic design of the LPU, response times are consistent resulting in our API providing the smallest range of variability. This means more repeatability and less effort designing around potential latency issues or slow responses.
We’re proud and excited to be leading this leaderboard in the initial phase of our ongoing roadmap for performance enhancements. Now, we already know what you’re thinking - “Groq has been saying they’re getting 270+ tokens per second per user for Llama-2 70B. What’s up with the difference?” As mentioned, this benchmark leverages a 150 output token count and includes input processing time as part of the calculation, rather than just solely the output tokens throughput. For example, if you were to test with 1000 output tokens, the result would be closer to the 270+ tokens/s per user you see on groq.com. All in all, we couldn’t be more excited to participate in our first public benchmark results with the world, thanks to the work of our team at Groq and the help of the great team at Anyscale. We look forward to providing benchmarking for Llama 2 7B, and who knows, we just might mix things up, with a variety of experts, beyond that. (Much) more to come.
Interested in API Access?
GroqCloud™ has multiple levels of API access. Learn more here.